跳转到主要内容成功标准参考
通过设定明确、可行的目标,并结合客观数据与用户体验进行评估,能减少主观偏差,更好满足实际使用需求。以下是声音模型的参考标准,可根据实际情况调整和使用。
- 任务完成度 评估模型将输入文本准确转化为语音的能力,词错误率(WER)是其中一个评估指标。该指标的计算方法是使用自动语音识别技术(ASR) 将合成语音转为文本后,与参考文本进行比对,统计替换、插入、删除错误的比例。
- 声音相似性 评估合成语音与目标参考音频在说话人特征上的相似程度。相似性(SIM)的计算方法为提取语音的 Embedding 信息,计算合成音频与参考音频 Embedding 的余弦相似度。
- 听感指标 衡量用户对合成语音质量的感知,PESQ 是一种客观听感评价指标,该指标将合成音频与一个高质量的“参考音频”进行比较,模拟人耳对音频的感知。
- 可懂度 评估合成语音的可理解程度,STOI 是评估语音可懂度的客观指标之一,衡量听众能听懂单句内容的程度。
- 主观选择比例 反映用户对合成音频的真实感受,常用评估方式包括 ELO 评分 和 比较平均意见分(CMOS)。
- ELO 评分:组织听众进行双音频对比测试(A/B 测试),每轮给出两段不同模型生成的音频,听众选择更偏好的版本。根据选择结果,使用 ELO 公式计算并更新各模型的评分,以反映其相对受欢迎程度。
- 比较平均意见分(CMOS):组织听众进行双音频对比测试(A/B 测试),让听众对两段音频样本的质量差异进行打分,将所有听众的评分取平均得到 CMOS,可反映模型生成音频的相对优势程度。
- 指令遵循 衡量模型在生成语音时是否准确执行输入指令,包括情感标签控制、提示词中的音色控制等。评估该标准可以提取合成语音的特征与指令进行对比,也可以采用 A/B 测试等主观评估的方式。
- 价格 评估使用模型的预算,需要考虑每次调用模型的成本、使用频率等因素。
- 响应速度 衡量模型从输入文本到生成语音的时间效率。在流式生成时,首包延时是量化指标之一,衡量从接收到完整的用户输入开始,到系统输出第一帧可播放音频数据包的时间间隔。
定义评估场景
Speech 模型可以应用在多个不同的场景。为了全面评估模型性能,在进行测试和评估时需要考虑模型在不同应用场景的表现。
- 声音克隆
声音克隆是语音个性化生成的核心能力,在该场景下可验证模型在零样本或少样本条件下复刻目标说话人的音色、语调和说话风格的能力和稳定性。
- 多语种生成
语音模型支持多种语言的合成能力,本场景需要评估模型在不同语言上的表现是否均衡,能否准确捕捉和合成各语言的特有发音及韵律特征。
- 跨语言合成
该场景反映模型将同一说话人的声音迁移到其他语言的能力,验证模型在保持目标音色一致性的同时,能否生成流畅自然且符合目标语言口音的音频。
- 情感控制
情感表达是影响语音感染力和用户体验的因素,本场景评估模型能否根据指令准确合成指定情绪(如愤怒、开心、悲伤等)的音频,并保持语音的自然度和可懂性。
- 文本驱动的音色合成
除克隆已有声音外,模型还具备根据自然语言描述生成全新音色的能力。此场景验证模型是否能够根据文本提示中的描述,生成符合预期的个性化语音。
结果和测试用例示例
MiniMax Speech-02 模型客观评估结果
- 声音克隆
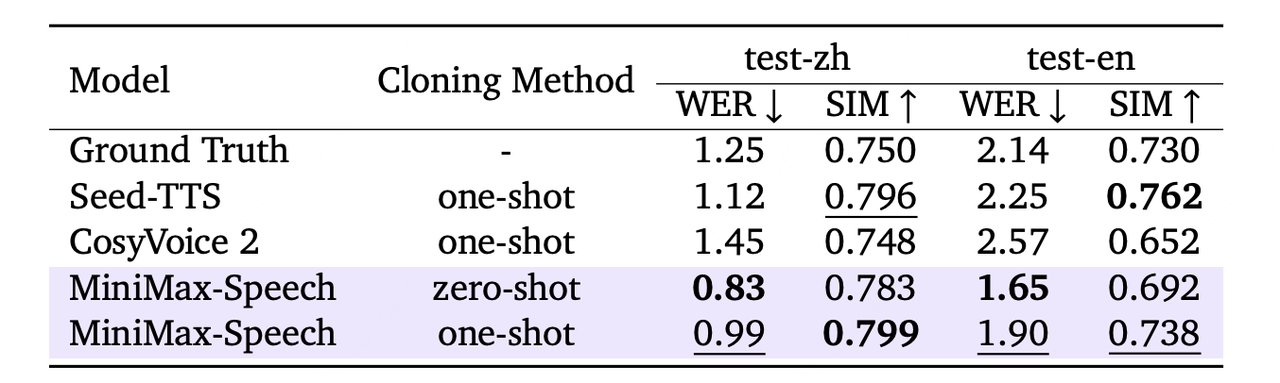
Speech 模型能够在仅提供目标说话人短暂参考音频以及提供参考音频及对应文本信息的情况下,实现高质量的声音克隆。实验结果表明,Speech 模型在中文和英文场景下,WER 和 SIM 指标均表现良好,反映了良好的音色克隆效果和任务完成度。
- 多语种生成
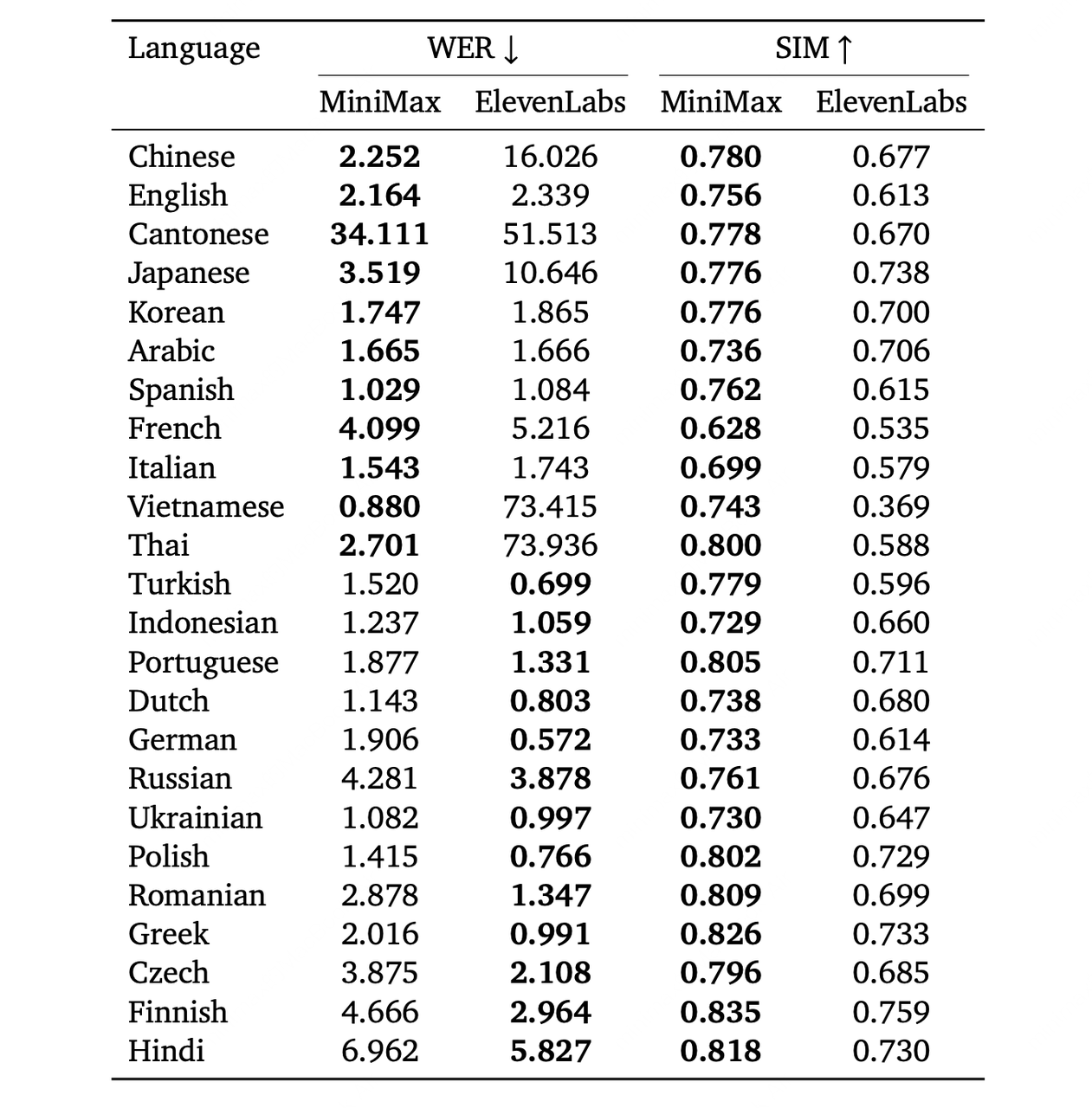
最新的 Speech-2.5 模型支持 40 种语言,在声音相似度较高的情况下,模型也表现出良好的准确性。 参考下图可了解模型在部分语种下的表现能力。
- 跨语言合成
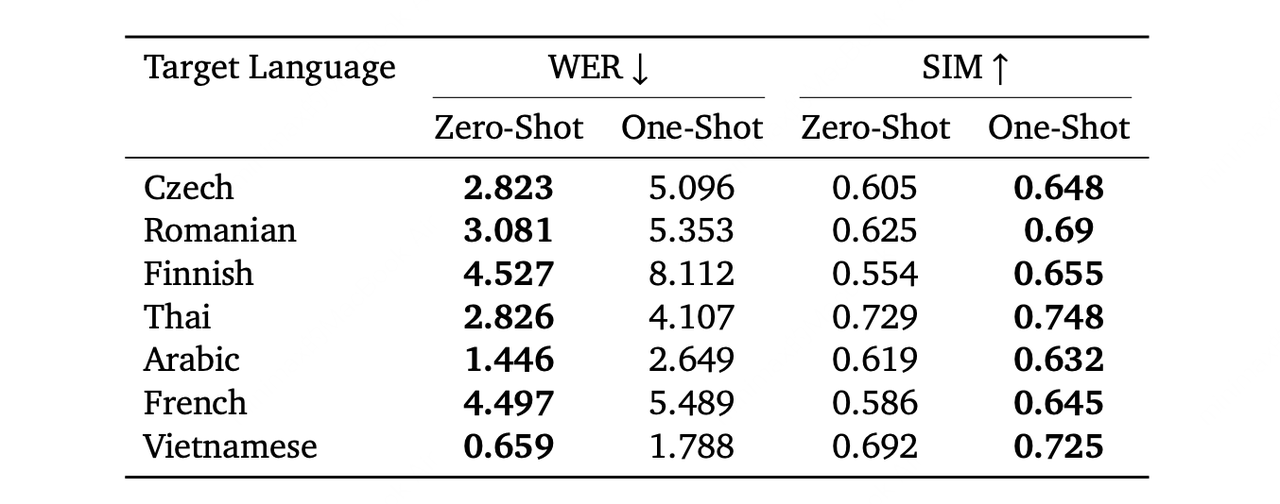
MiniMax Speech-02 模型具有良好的跨语言合成能力,能够基于一小段语音片段合成其他语言的音频。以中文为源语言的实验结果表明,零样本克隆的准确率更高,而单样本克隆的声音相似度更好。
MiniMax Speech-02 测试用例
- 声音克隆
- 音频描述:吸引人且具有说服力的演讲者声音
- 音频描述:具有低音共振和空间感的机器人声音
- 多语种生成
- 跨语言合成
- 情感控制
- 文本控制的音色合成
- 中文示例
-
提示词 男性中年声音,说中文,音色浑厚醇厚,带有自然的磁性,语速偏慢,音量适中,音调偏低沉。声音整体给人沉稳可靠的感觉,在深度访谈场景中表现出专业性和亲和力,音质清晰,吐字规整有力。
-
合成音频
- 英文示例
-
提示词 English-speaking female voice, sounding relatively young, with a sweet and pleasant tone. Speaking at a moderate pace with a touch of energy, similar to someone narrating a beauty/makeup tutorial video. The overall atmosphere is relaxed and cheerful.
-
合成音频
更多测试用例可参考技术报告,您也可以通过 Audio 调试台 进行语音合成的实时调试和效果预览。